对象及其关系在我们周围是无处不在的,关系对于理解对象的重要性可以与对象本身的属性一样重要,例如: 交通网络、生产网络、知识图谱或社交网络。离散数学和计算机科学长期以来一直在将这些网络形式化为图, 由节点以各种不规则方式连接的边组成。然而,大多数机器学习(ML)算法只允许输入对象之间的规则和统 一关系,比如像素网格、单词序列或根本没有关系。
图神经网络(GNN)作为一种强大的技术,利用了图的连接性(类似于旧算法DeepWalk和Node2Vec)以及各 个节点和边上的输入特征。GNN可以对整个图进行预测(这种分子会以某种方式发生反应吗?)、对单个节点 进行预测(根据其引用,这个文档的主题是什么?)或对潜在边进行预测(这个产品是否可能与那个产品一起 购买?)。除了对图进行预测外,GNN还是一个强大的工具,用于弥合更典型的神经网络用例之间的鸿沟。它 以连续方式编码图的离散关系信息,从而可以自然地包含到另一个深度学习系统中。
我们很高兴地宣布推出 TensorFlow GNN 1.0(TF-GNN),这是一个经过实际测试的用于大规模构 建GNN的库。它支持在TensorFlow中进行建模和训练,以及从庞大的数据存储中提取输入图。TF-GNN是从头开 始为异构图构建的,其中类型和关系由不同的节点和边集表示。现实世界中的对象及其关系以不同类型出现,TF-GNN 的异构重点使其自然地表示这些对象及其关系。
在TensorFlow内部,这些图由类型为tfgnn.GraphTensor的对象表示。这是一种复合张量类型(在一个Python
类中包含多个张量),可以作为tf.data.Dataset、tf.function等中的一等公民被接受。它存储了图结构以及
附加到节点、边和整个图上的特征。可以将GraphTensors的可训练变换定义为高级Keras API中的Layers对象,
也可以直接使用tfgnn.GraphTensor原语。
GNNs:在上下文中对对象进行预测
为了说明问题,让我们来看看TF-GNN的一个典型应用:在由交叉引用大型数据库的表定义的图中,预测某种类型节点的属性。 例如,计算机科学(CS)arXiv论文的引用数据库,具有一对多的引用��关系和多对一的被引关系,我们希望预测每篇论文的主题领域。
与大多数神经网络一样,GNN是在许多带标签的示例数据集(约数百万个)上进行训练的,但每个训练步骤只包括一个更小的批处理 训练示例(比如说,数百个)。为了扩展到数百万个,GNN在基础图中的一系列相对较小的子图上进行训练。每个子图包含足够的原始数据, 以计算标记节点的GNN结果并训练模型。这个过程——通常称为子图采样——对于GNN的训练非常重要。大多数现有的工具都是以批处理方式进 行采样,生成静态子图进行训练。TF-GNN提供了改进这一点的工具,通过动态和交互式采样。
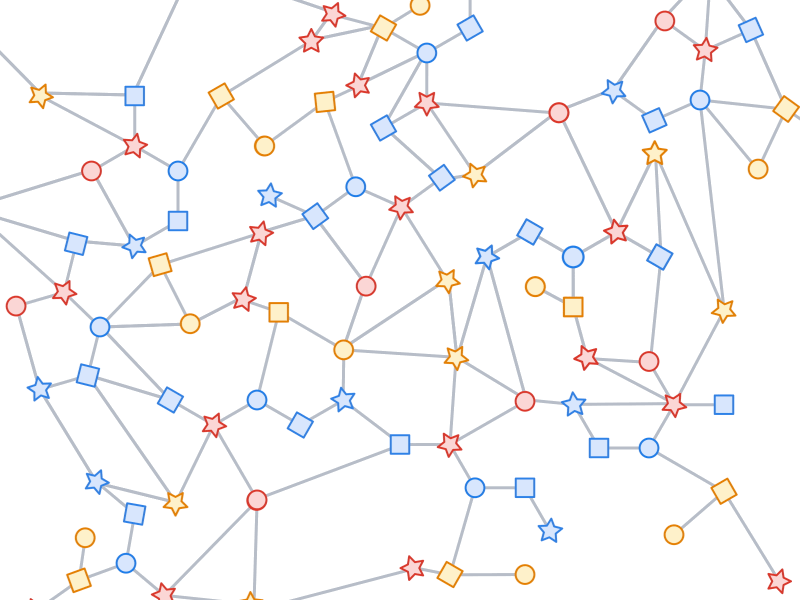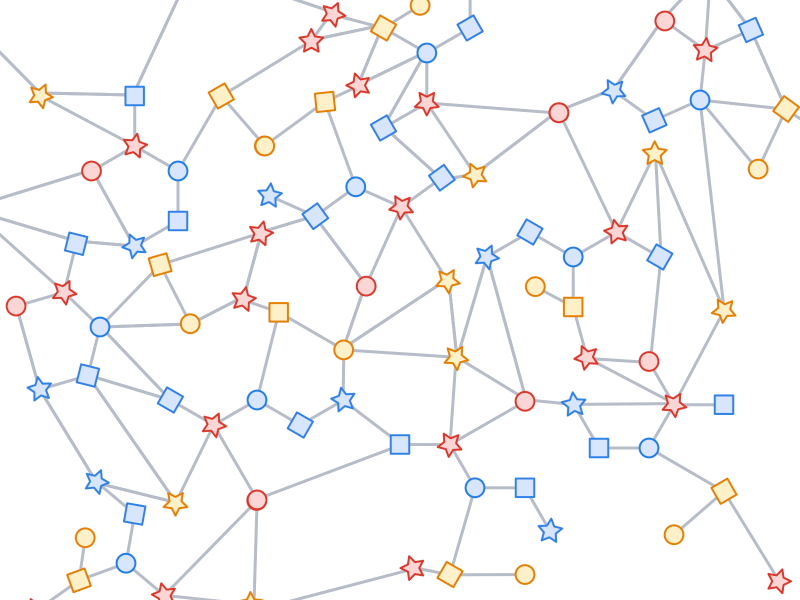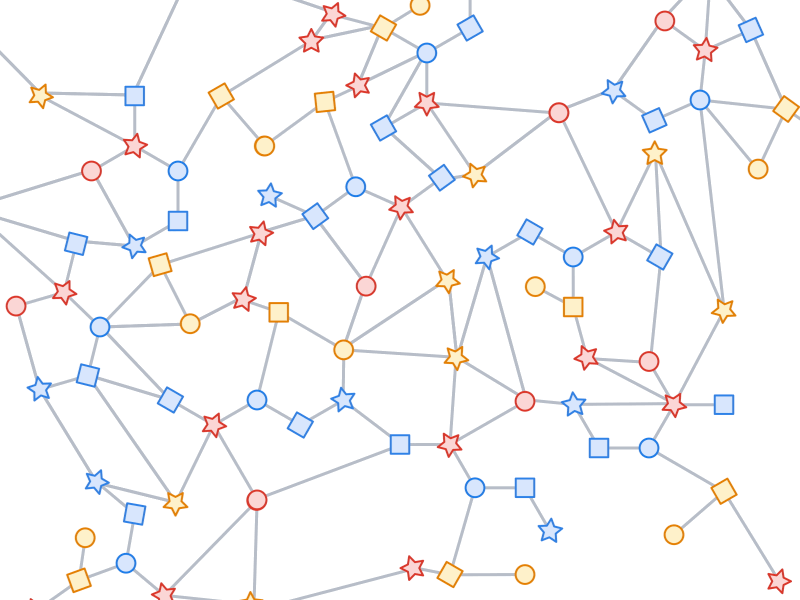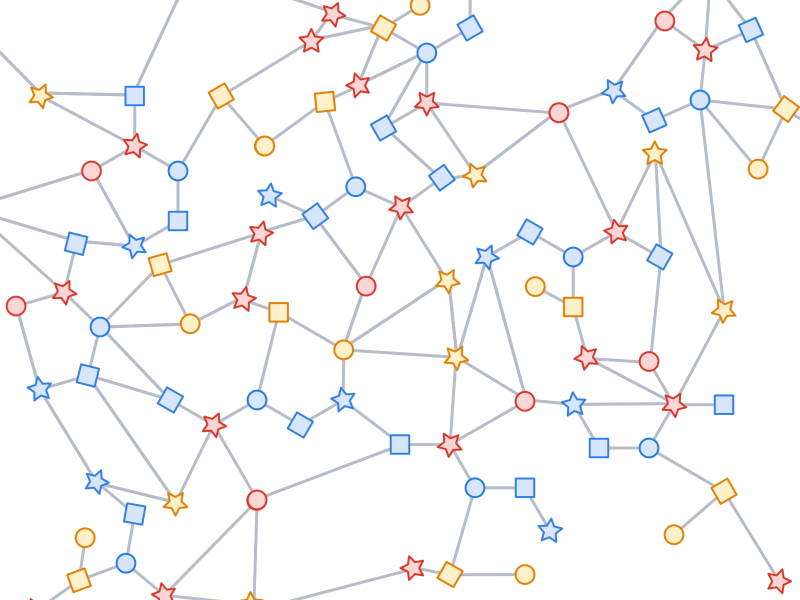
TF-GNN 1.0 首次推出了灵活的 Python API,用于配置所有相关规模的动态或批量子图采样:在 Colab 笔记本(如本笔记本)中交互式采样, 用于对存储在单个训练主机主内存中的小型数据集进行高效采样,或通过 Apache Beam 对存储在网络文件系统中的庞大数据集(多达数亿节点和 数十亿条边)进行分布式采样。详情请分别参阅我们的内存采样和基于束的采样用户指南。
在这些相同的采样子图上,GNN 的任务是计算根节点的隐藏(或潜在)状态;隐藏状态聚合并编码根节点邻域的相关信息。一种经典的方法是消息 传递神经网络。在每一轮消息传递中,节点会沿着传入边接收来自邻居的消息,并根据这些消息更新自己的隐藏状态。经过 n 轮后,根节点的隐藏 状态就会反映出 n 条边上所有节点的总信息(如下图 n = 2)。信息和新的隐藏状态由神经网络的隐藏层计算。在异构图中,对不同类型的节点 和边使用单独训练的隐藏层通常是有意义的。

与其他神经网络训练一样,在 GNN 的隐藏状态上为标注节点设置一个输出层,计算损失(衡量预测误差),并通过反向传播更新模型权重,训练设置就完成了。
除了有监督的训练(即最小化由标签定义的损失),GNN 还可以无监督的方式(即不带标签)进行训练。这样,我们就能计算出节点离散图结构及其特征的 连续表示(或嵌入)。这些表示通常用于其他 ML 系统。这样,由图编码的离散关系信息就能被纳入更典型的神经网络用例中。TF-GNN 支持对异构图的无 监督目标进行细粒度规范。
构建 GNN 架构
TF-GNN 库支持构建和�训练不同抽象层次的 GNN。
在最高级别,用户可以使用该库捆绑的任何预定义模型,这些模型以 Keras 层表达。除了一小部分研究文献中的模型之外,TF-GNN 还附带了一个高度可配置 的模型模板,该模板提供了经过精心挑选的建模选择,我们发现这些选择为我们的许多内部问题提供了强有力的基准。模板实现了 GNN 层;用户只需初始化 Keras 层即可。
import tensorflow_gnn as tfgnn
from tensorflow_gnn.models import mt_albis
def model_fn(graph_tensor_spec: tfgnn.GraphTensorSpec):
"""Builds a GNN as a Keras model."""
graph = inputs = tf.keras.Input(type_spec=graph_tensor_spec)
# Encode input features (callback omitted for brevity).
graph = tfgnn.keras.layers.MapFeatures(
node_sets_fn=set_initial_node_states)(graph)
# For each round of message passing...
for _ in range(2):
# ... create and apply a Keras layer.
graph = mt_albis.MtAlbisGraphUpdate(
units=128, message_dim=64,
attention_type="none", simple_conv_reduce_type="mean",
normalization_type="layer", next_state_type="residual",
state_dropout_rate=0.2, l2_regularization=1e-5,
)(graph)
return tf.keras.Model(inputs, graph)
在最底层,用户可以根据在图中传递数据的原语,从头开始编写 GNN 模型,例如将数据从一个节点广播到它的所有传出边,或将数据从它的所有传入边汇集到一个节点(例 如计算传入信息的总和)。当涉及特征或隐藏状态时,TF-GNN 的图数据模型对节点、边和整个输入图一视同仁,因此不仅能直接表达以节点为中心的模型(如上文讨论的 MPNN),还能表达更一般形式的图网络。在核心 TensorFlow 的基础上,可以使用 Keras 作为建模框架,但没有必要这样做。有关更多细节和建模的中间层次, 请参阅 TF-GNN 用户指南和模型集。
训练编排
虽然高级用户可以自由地进行自定义模型训练,但 TF-GNN Runner 还提供了一种简洁的方法来协调常见情况下 Keras 模型的训练。 一个简单的调用可能如下所示:
from tensorflow_gnn import runner
runner.run(
task=runner.RootNodeBinaryClassification("papers", ...),
model_fn=model_fn,
trainer=runner.KerasTrainer(tf.distribute.MirroredStrategy(), model_dir="/tmp/model"),
optimizer_fn=tf.keras.optimizers.Adam,
epochs=10,
global_batch_size=128,
train_ds_provider=runner.TFRecordDatasetProvider("/tmp/train*"),
valid_ds_provider=runner.TFRecordDatasetProvider("/tmp/validation*"),
gtspec=...,
)
The Runner为ML问题提供了现成的解决方案,如分布式训练和在Cloud TPUs上对tfgnn.GraphTensor进行固定形状填充。除了对单个任务进行训练(如上所示),
它还支持同时对多个(两个或更多)任务进行联合训练。例如,无监督任务可以与监督任务混合,以提供特定应用的归纳偏差的最终连续表示(或嵌入)。调用者只需
要用任务映射替换任务参数即可:
from tensorflow_gnn import runner
from tensorflow_gnn.models import contrastive_losses
runner.run(
task={
"classification": runner.RootNodeBinaryClassification("papers", ...),
"dgi": contrastive_losses.DeepGraphInfomaxTask("papers"),
},
...
)
此外,TF-GNN Runner 还包括用于模型归因的集成梯度实现。集成梯度输出是一个 GraphTensor,其连接性与观察到的 GraphTensor 相同,但其特征用梯度值代替,
在 GNN 预测中,较大的梯度值比较小的梯度值贡献更多。用户可以检查梯度值,查看其 GNN 使用最多的特征。
结论
总之,我们希望 TF-GNN 能够推动 GNN 在 TensorFlow 中的大规模应用,并促进该领域的进一步创新。如果您想了解更多信息,请尝试我们使用流行的 OGBN-MAG 基准进行的 Colab 演示(在浏览器中进行,无需安装),浏览我们的其他用户指南和 Colab,或阅读我们的论文。