Model Explorer是一个强大的图形可视化工具,帮助人们理解、调试和优化机器学习模型。 它专注于以直观的分层格式可视化大型图形,但也适用于较小的模型。
图形可视化在机器学习(ML)开发过程中起着至关重要的作用。 模型的视觉表示帮助研究人员和工程师调试转换和量化问题,识别性能瓶颈,找到优化模式(例如,操作融合),并深入了解模型架构。
这些实践对许多类型的模型都很有用,特别是在将模型部署到资源有限的设备(如手机和浏览器)时。 然而,现代ML和AI模型(例如Transformers和diffusers)的规模和复杂性不断增加,这给现有的可视化工具带来了重大挑战。
大规模基于Transformer的模型通常会使传统的图形可视化工具不堪重负,导致渲染失败或视觉复杂度难以管理。 此外,缺乏清晰的视觉层次结构使人们难以理解节点之间的关系。
为了解决这些限制,我们推出了Model Explorer,
这是一种新颖的图形可视化解决方案,可以顺畅处理大型模型并可视化分层信息,如函数名称和作用域。
Model Explorer支持多种图形格式,包括JAX、PyTorch、TensorFlow和TensorFlow Lite使用的格式。
最初作为谷歌研究人员和工程师的实用工具开发,Model Explorer现在作为我们谷歌AI Edge产品系列的一部分向公众开放。
Model Explorer在简化将大型模型部署到设备平台方面特别有效,其中可视化转换、量化和优化数据尤为有用。
我们描述了Model Explorer如何将用于3D游戏和动画制作的图形技术(例如实例化渲染和多通道有符号距离场(MSDF))相结合, 并将其应用于ML图形渲染。 我们展示了Model Explorer为开发大型模型提供了三种用例:理解模型架构、调试转换错误以及调试性能和数字问题。

大型图形可视化中的挑战
将大型模型图形可视化存在两个主要技术挑战。 首先,布局算法难以随着图形规模的增长而扩展:随着节点数量的增加,它们的计算复杂性急剧上升,导致布局阶段明显减慢,甚至偶尔完全失败。 即使成功的布局也往往过于密集和复杂,降低了可解释性。
其次,大多数现有的模型可视化工具使用基于可缩放矢量图形的渲�染,这种渲染不适用于渲染大量对象。 缩放和滚动操作变得迟缓和无响应,使可视化工具无法使用。
受Tensorboard图形可视化器中分层布局概念的启发,我们开发了一个库,从像TensorFlow、PyTorch和JAX这样的主流创作框架中提取分层信息。 然后,我们构建了一个交互式系统,从最顶层开始可视化节点,允许用户通过逐层展开或折叠层来逐步浏览图形。 这使用户能够按需检查图形内部结构和连接。
由于布局算法是基于每层进行操作的,Model Explorer在用户选择打开一层时计算布局, 这种方法避免了在初始图形加载期间对所有节点进行不必要的计算,并显著改善了大型模型的性能。
我们通过在WebGL和three.js中实现GPU加速图形渲染来解决第二个挑战。 因此,我们实现了每秒60帧(FPS)的流畅用户体验,即屏幕每秒显示60幅图像, 即使包含数万个节点的图形也能创建平滑和逼真的交互和动画效果。 此外,我们利用实例化渲染技术在场景中同时渲染对象的多个副本。 下面的示例展示了一个包含50,000个节点和5,000条边的图形(为演示目的随机生成)如何在2019年款Macbook Pro上的集成GPU上以60 FPS的流畅度呈现。 为了提高视觉连续性,我们为层导航添加了平滑动画,帮助用户保持对模型结构位置的理解。

理解模型架构
通过基于层的视图和导航复杂结构的能力,大型模型变得更容易理解。 例如,在下面的MobileBert模型中,很明显自注意力掩码和嵌入被馈送到一个Transformer层中。嵌入层的扩展视图显示了不同类型嵌入之间的关系。总共有近2,000个节点,没有这些分层信息,这个模型几乎是不可能理解的。
具有自注意力掩码、嵌入和Transformer层等层信息,有助于理解模型架构](https://storage.googleapis.com/gweb-research2023-media/images/model-explorer-layer-info-img.original.png)
调试转换错误
在部署到特定硬件(如手机或笔记本电脑)之前,ML模型必须经过转换过程:例如将PyTorch模型转换为Tensorflow Lite模型。 然而,在转换过程中往往会丢失有关转换的信息。
为了比较多个图形,Model Explorer提供了并排比较模式。
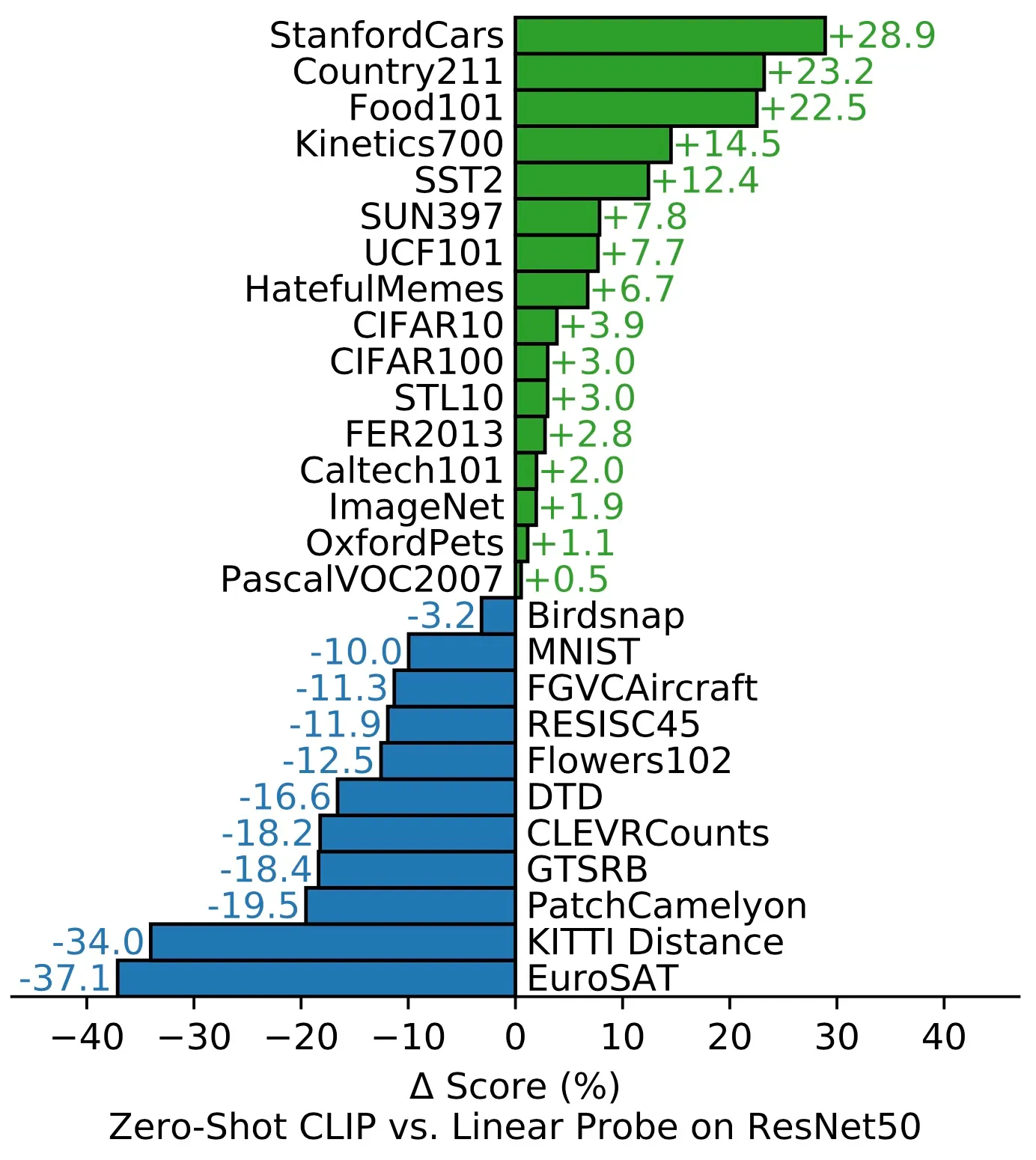
下面的示例突出显示了在从PyTorch到TensorFlow Lite的转换过程中一个层内的子图(即torch.nn.modules.linear.Linear_attn)的变化。
比较层的输入和输出的形状和数据类型信息可以帮助突出转换错误。
调试性能和数字准确性
另一个Model Explorer的功能是能够在图上叠加每个节点的数据, 允许用户使用数据中的值对节点进行排序、搜索和样式化。
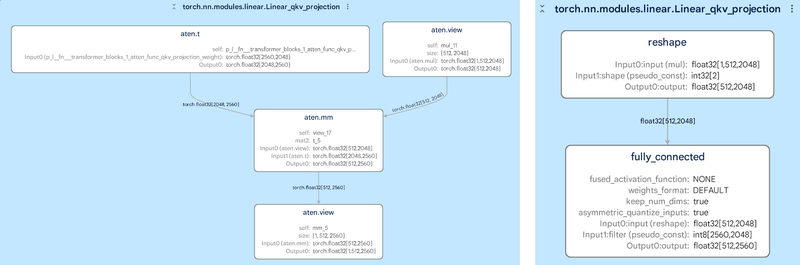
与分层视图相结合,我们用户研究中的参与者表示,这有助于他们快速缩小图中某个区域的性能或数值问题, 如果没有这种可视化,这些见解将会更加难以捉摸。 下面的示例显示了量化 TFLite 模型的均方误差与其浮点数对照模型的情况。
使用 Model Explorer,用户能够快速确定质量下降发生在图的底部附近,并调整他们的量化方法。
安装和启动Model Explorer
- 安装
pip install model-explorer
- 启动
model-explorer
-
打开浏览器,输入
http://localhost:8080,即可查看模型可视化。 -
拖拽或者点击上传模型文件,即可查看模型结构。
结论
Model Explorer引入了一种强大的新方式,可以在几乎任何规模的模型中检查架构并调试问题, 而不会影响用户体验或呈现性能。
它以清晰的方式呈现模型结构,使用层和分组来提高理解,并融入调试特性和层级洞察力,以支持模型分析。 Model Explorer现在已公开。请访问Model Explorer网站 以获取安装说明,并提供反馈。