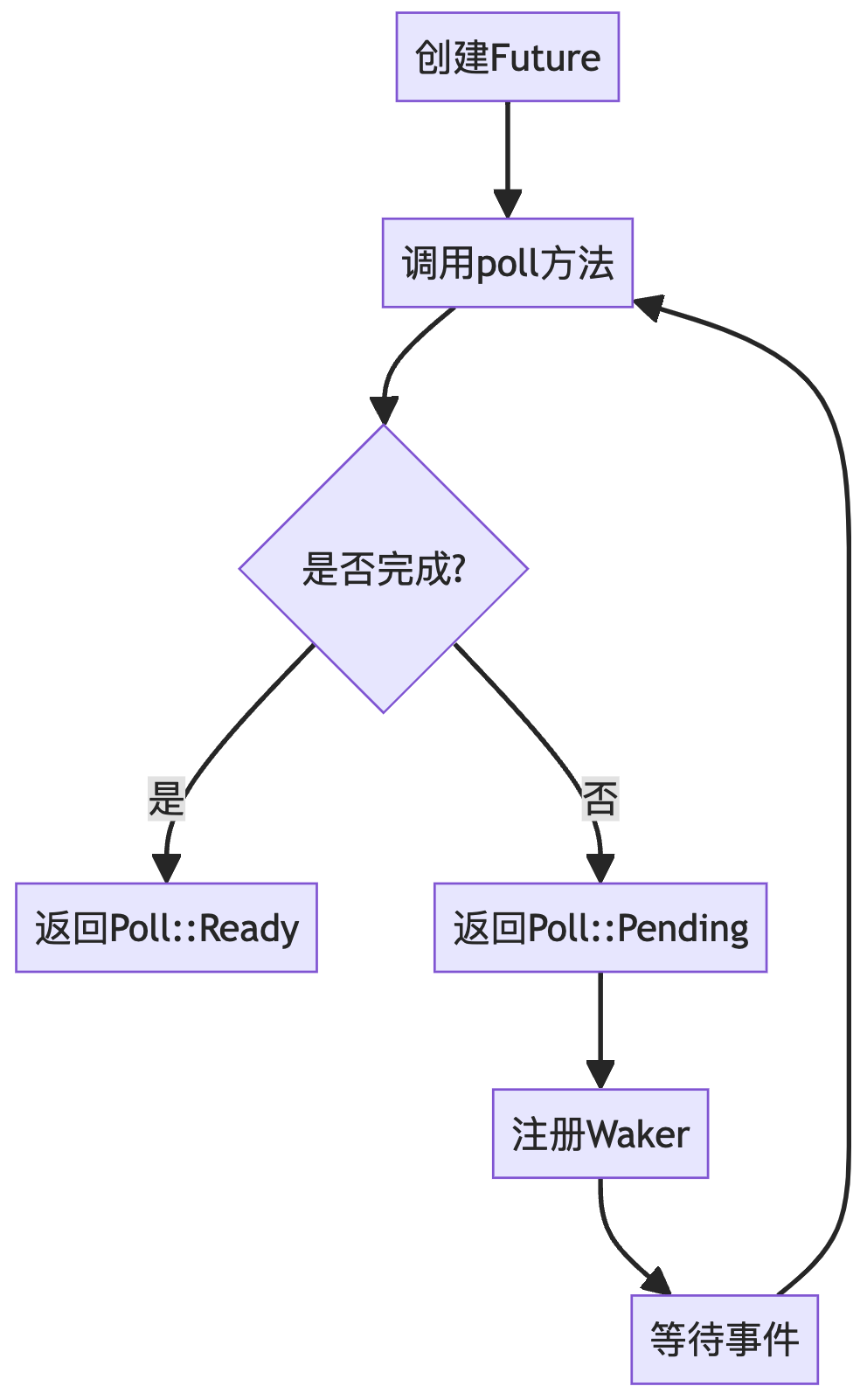
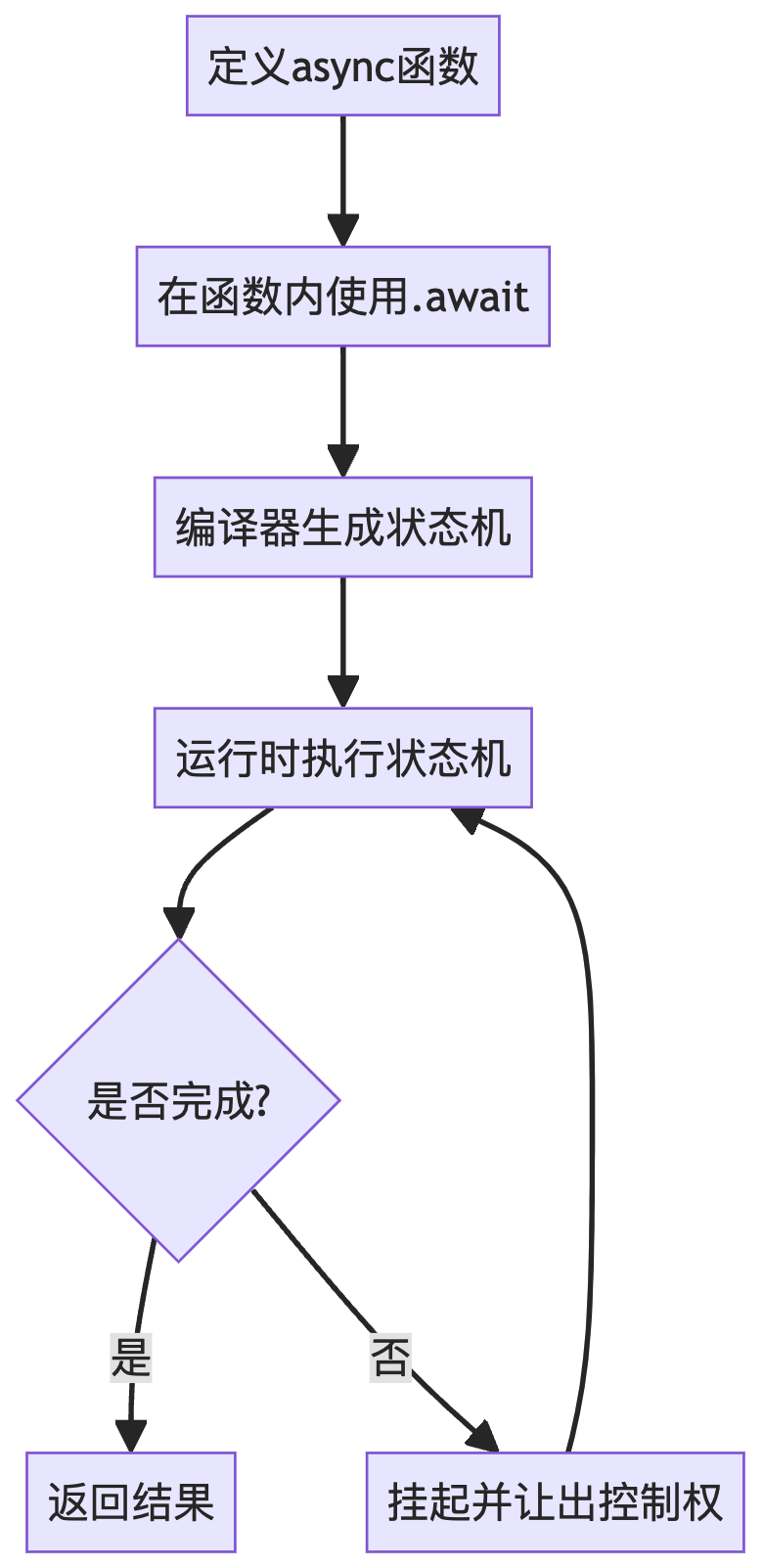
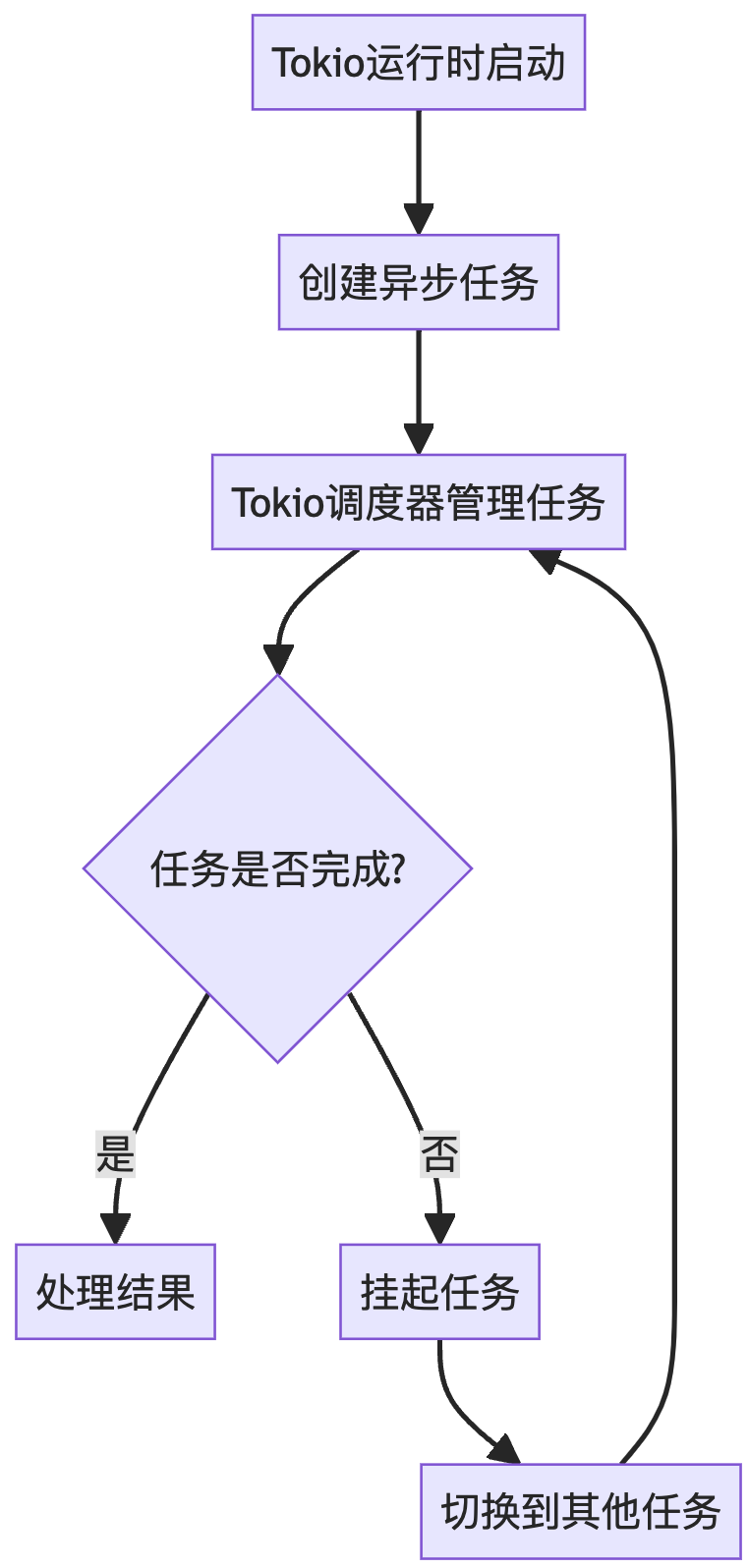
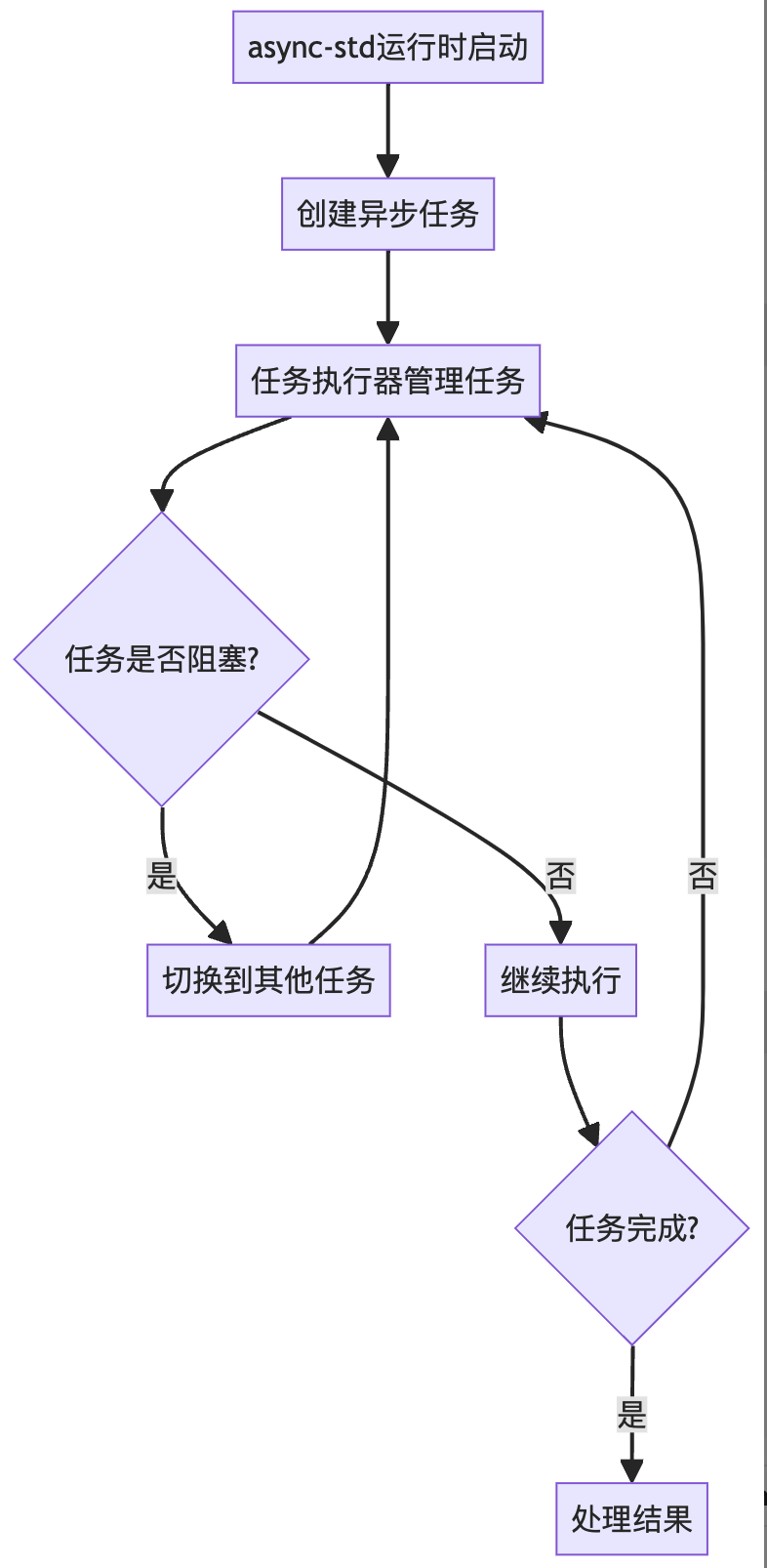
Rust生态系统中一个纯Rust实现的Actor框架——Ractor。构建于Tokio之上。
它受Erlang的gen_server启发,同时具备Rust的速度和性能优势!
引言
在软件开发中,时间是有限的资源。你和我只有一小段时间来编写软件。而在同样的时间块内,有些人能够构建出令人惊叹的软件,而另一些人则困在项目的边缘,进行一些他们从未真正理解的小改动。你可能会认为这是随机的,或者试图找出为什么有些人能极大地提高生产力,而另一些人却在同样的问题上反复挣扎。
在你对我竖起叉子之前,我并不是在谈论那些在财务上取得成功或拥有大量用户的软件。我们都知道,与其他产品相比,Microsoft Teams的质量并不出众,但它拥有数量级更多的用户。商业策略如捆绑销售可能使产品质量变得无关紧要,只要你关注的是用户数量。我所说的是构建优秀的软件;我希望开发出其他像我一样喜欢的软件。你不也是这样吗?
一些需要记住的符号
在深入本教程之前,有几个符号需要澄清,以便读者能够更好地理解内容。
消息传递的Actors
由于我们试图尽可能地模仿Erlang的实践,Ractor中的消息发送可以通过两种方式进行:
- First-and-Forget(发送后不等待回复):对应Erlang中的
cast。 - 等待回复(等待消息处理后的回复):对应Erlang中的
call。
这种命名方式遵循了Erlang的命名约定,使得开发者在使用Ractor时能够更容易理解和上手。
安装Ractor
要在你的Rust项目中使用Ractor,只需在Cargo.toml文件的依赖部分添加以下内容:
[dependencies]
ractor = "0.9"
然后运行cargo build以安装Ractor。
第一个Actor
当然,我们需要从标志性的“Hello World”示例开始。我们希望构建一个Actor,每收到一条消息就打印“Hello World”。首先,我们定义消息类型,然后定义Actor本身。
定义消息类型
pub enum MyFirstActorMessage {
/// 打印“Hello World”
PrintHelloWorld,
}
定义Actor
use ractor::{Actor, ActorRef, ActorProcessingErr};
pub struct MyFirstActor;
#[async_trait::async_trait]
impl Actor for MyFirstActor {
type State = ();
type Msg = MyFirstActorMessage;
type Arguments = ();
async fn pre_start(&self, _myself: ActorRef<Self::Msg>, _arguments: Self::Arguments)
-> Result<Self::State, ActorProcessingErr>
{
Ok(())
}
}
解析
-
结构体定义:首先定义一个空的结构体
MyFirstActor,它将作为我们的Actor。 -
实现
Actortrait:通过#[async_trait::async_trait]宏实现Actortrait,定义以下关联类型:State:Actor的状态,这里是空的(),表示无状态。Msg:Actor处理的消息类型,即我们定义的MyFirstActorMessage。Arguments:Actor启动时的参数,这里也是空的()。
-
pre_start方法:定义Actor启动时的初始化逻辑,这里我们返回一个空的状态Ok(())。
�添加消息处理
现在,如何让Actor在接收到消息时打印“Hello World”呢?我们需要实现消息处理逻辑。
#[async_trait::async_trait]
impl Actor for MyFirstActor {
type State = ();
type Msg = MyFirstActorMessage;
type Arguments = ();
async fn pre_start(&self, _myself: ActorRef<Self::Msg>, _arguments: Self::Arguments)
-> Result<Self::State, ActorProcessingErr>
{
Ok(())
}
async fn handle(&self, _myself: ActorRef<Self::Msg>, message: Self::Msg, _state: &mut Self::State)
-> Result<(), ActorProcessingErr>
{
match message {
MyFirstActorMessage::PrintHelloWorld => {
println!("Hello World!");
}
}
Ok(())
}
}
解析
handle方法:实现handle方法,用于处理每一条接收到的消息。- 当收到
PrintHelloWorld消息时,打印“Hello World!”。
- 当收到
运行第一个Actor
将所有部分组合在一起,创建一个完整的程序。
#[tokio::main]
async fn main() {
// 启动Actor,并获取其引用和JoinHandle
let (actor, actor_handle) = Actor::spawn(None, MyFirstActor, ()).await.expect("Actor failed to start");
for _ in 0..10 {
// 发送消息,不等待回复
actor.cast(MyFirstActorMessage::PrintHelloWorld).expect("Failed to send message to actor");
}
// 等待一段时间,让所有消息都有机会被处理
tokio::time::sleep(tokio::time::Duration::from_millis(100)).await;
// 清理资源,停止Actor
actor.stop(None);
actor_handle.await.unwrap();
}
解析
- 启动Actor:使用
Actor::spawn方法启动MyFirstActor,并获取其引用actor和JoinHandle``actor_handle。 - 发送消息:通过
actor.cast方法发送10条PrintHelloWorld消息,Actor会依次处理并打印“Hello World!”。 - 等待处理:使用
tokio::time::sleep等待100毫秒,确保所有消息都有机会被处理。 - 停止Actor:调用
actor.stop(None)停止Actor,并等待actor_handle完成。
添加状态
现在,如果我们希望Actor能够维护一些状态,例如记录它已经打印了多少次“Hello World”,该如何做呢?让我们来看�一个具体的例子。
修改消息类型
use ractor::{Actor, ActorRef, ActorProcessingErr, RpcReplyPort};
pub enum MyFirstActorMessage {
/// 打印“Hello World”
PrintHelloWorld,
/// 回复已经打印的“Hello World”次数
HowManyHelloWorlds(RpcReplyPort<u16>),
}
修改Actor定义
pub struct MyFirstActor;
#[async_trait::async_trait]
impl Actor for MyFirstActor {
type State = u16; // 状态为打印次数
type Msg = MyFirstActorMessage;
type Arguments = ();
async fn pre_start(&self, _myself: ActorRef<Self::Msg>, _arguments: Self::Arguments)
-> Result<Self::State, ActorProcessingErr>
{
Ok(0) // 初始状态为0
}
async fn handle(&self, _myself: ActorRef<Self::Msg>, message: Self::Msg, state: &mut Self::State)
-> Result<(), ActorProcessingErr>
{
match message {
MyFirstActorMessage::PrintHelloWorld => {
println!("Hello World!");
*state += 1; // 增加打印次数
}
MyFirstActorMessage::HowManyHelloWorlds(reply) => {
if reply.send(*state).is_err() {
println!("监听者在我们发送回复之前已经丢弃了端口");
}
}
}
Ok(())
}
}
解析
- 状态定义:将
State类型从()修改为u16,用于记录打印次数。 - 消息类型扩展:添加
HowManyHelloWorlds消息类型,包含一个RpcReplyPort<u16>,用于回复打印次数。 - 处理消息:
PrintHelloWorld:打印“Hello World!”并增加状态中的计数。HowManyHelloWorlds:通过reply.send方法回复当前的打印次数。
运行有状态的示例
结合有状态的Actor,编写一个完整的程序,演示如何获取Actor的状态。
#[tokio::main]
async fn main() {
// 启动Actor,并获取其引用和JoinHandle
let (actor, actor_handle) =
Actor::spawn(None, MyFirstActor, ())
.await
.expect("Actor failed to start");
for _ in 0..10 {
// 发送打印消息
actor.cast(MyFirstActorMessage::PrintHelloWorld)
.expect("Failed to send message to actor");
}
// 发送查询消息,并等待回复,设置超时为100ms
let hello_world_count =
ractor::call_t!(actor, MyFirstActorMessage::HowManyHelloWorlds, 100)
.expect("RPC failed");
println!("Actor replied with {} hello worlds!", hello_world_count);
// 清理资源,停止Actor
actor.stop(None);
actor_handle.await.unwrap();
}
解析
- 启动Actor:与之前相同,启动
MyFirstActor。 - 发送消息:发送10条
PrintHelloWorld消息,Actor会打印“Hello World!”并记录次数。 - 查询状态:使用
ractor::call_t!宏发送HowManyHelloWorlds消息,等待回复并获取打印次数。 - 打印结果:输出Actor回复的打印次数。
- 清理资源:停止Actor并等待其完成。
宏解释
cast!:发送消息而不等待回复,相当于actor.cast(MESG)。call!:发送消息并等待回复,相当于actor.call(|reply| MESG(reply))。call_t!:与call!类似,但带有超时参数,用于防止长时间等待。
总结
通过本教程,我们学习了如何使用Ractor在Rust中实现Actor模型,涵盖了以下内容:
- 基本概念:了解Actor模型及其在Rust中的实现。
- 消息传递:掌握
cast和call两种消息传递方式。 - 安装Ractor:在项目中引入Ractor框架。
- 创建第一个Actor:编写一个简单的打印“Hello World”的Actor。
- 添加状态:扩展Actor以维护状态,并通过消息查询状态。
- 运行示例:结合所有部分,编写并运行一个完整的有状态示例程序。
关键要点
- Actor模型:一种并发编程模型,通过消息传递实现不同Actor之间的通信和协作。
- Ractor框架:受Erlang启发,提供高性能的Actor实现,构建于Tokio之上。
- 消息类型:使用枚举定义不同的消息类型,明确Actor可以处理的行为。
- 状态管理:Actor可以维护内部状态,并通过消息进行查询和更新。
- 宏工具:Ractor提供了便捷的宏,如
cast!和call_t!,简化消息发送和回复的流程。
通过掌握这些内容,你可以在Rust中构建高效、可靠的并发应用,充分利用Rust的所有权和安全特性,编写出高质量的软件。