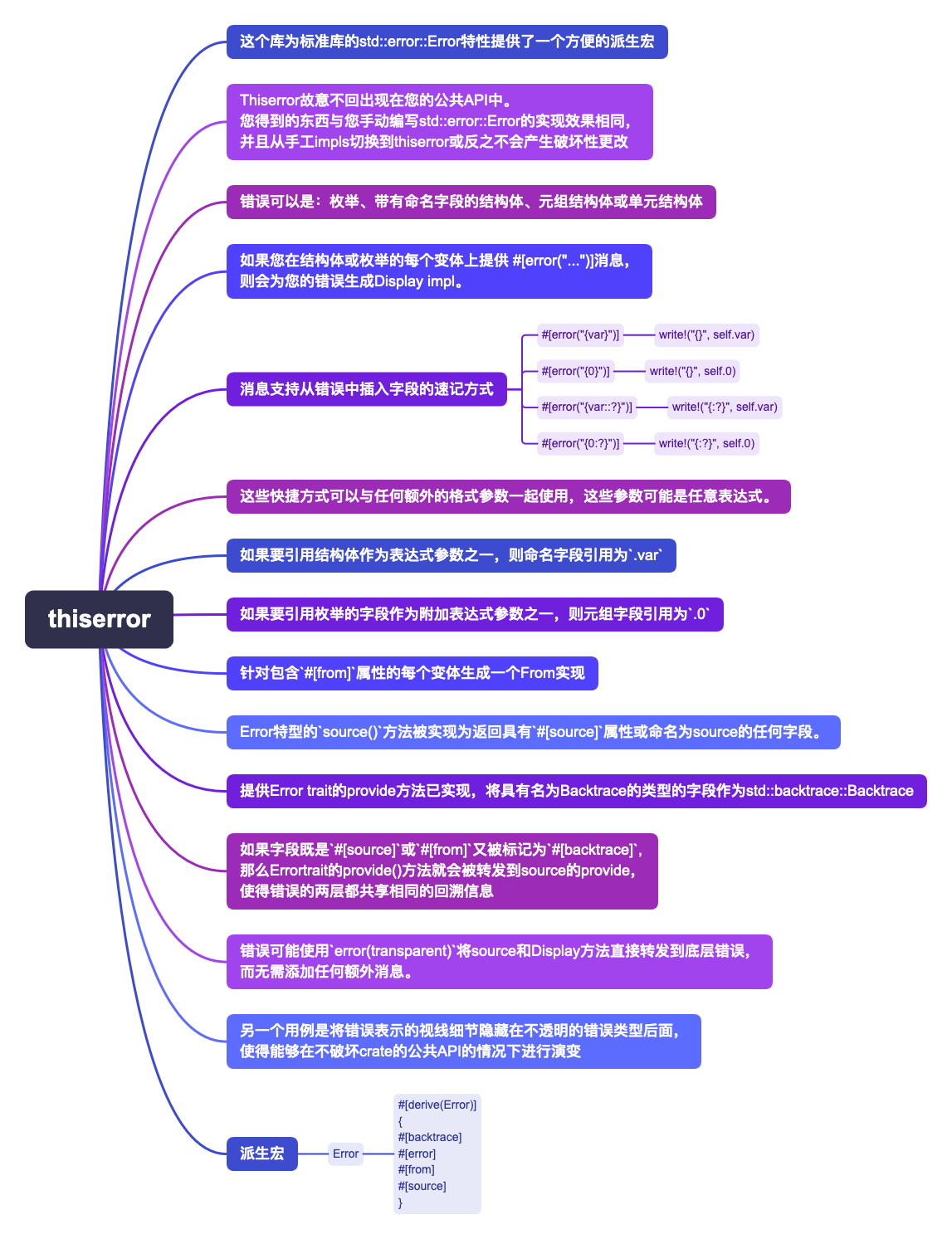
pub struct Router<S = ()> { }
用于组合处理程序和服务的路由器类型。
impl<S> Router<S>
where
S: Clone + Send + Sync + 'static,
创建一个新的路由器,除非您添加额外的路由,否则将对所有请求响应404未找到。
pub fn route(self, path: &str, method_router: MethodRouter<S>) -> Self
path: 是由/分割的路径段字符串。每个段可能是静态的、捕获的或者是通配符。method_router: 是一个MethodRouter,它将请求方法映射到处理程序。
method_router通常会是类似于get的方法路由器中的处理程序。
例如:
如果传入的请求路径完全匹配,则将调用相应的服务。
例如:
/:key/foo/:key/users/:id/tweets
路径可以包含类�似于/:key的段,它匹配任何单个段,并将存储在key处捕获的值。
捕获的值可以是零长度,除了无效路径//
捕获可以使用Path进行提取。
MatchedPath可以用于提取匹配路径,而不是实际路径。
路径可以以/*key结尾,匹配所有段并捕获的段存储在key中。
例如:
/*key/users/*path/:id/:repo/*tree
请注意,/*key 不匹配空段。因此:
/*key 不匹配 /,但匹配 /a,/a/ 等。/x/*key 不匹配 /x 或 /x/,但匹配 /x/a,/x/a/ 等。
还可以使用 Path 来提取通配符捕获。
请注意,不包括前导斜杠,即对于路由 /foo/*rest 和路径 /foo/bar/baz,
rest 的值将是 bar/baz。
要接受同一路由的多个方法,您可以同时添加所有处理程序。
use axum::{Router, routing::{get, delete}, extract::Path};
let app = Router::new().route(
"/",
get(get_root).post(post_root).delete(delete_root),
);
async fn get_root() {}
async fn post_root() {}
async fn delete_root() {}
或者你也可以一一添加:
let app = Router::new()
.route("/", get(get_root))
.route("/", post(post_root))
.route("/", delete(delete_root));
更多例子
use axum::{Router, routing::{get, delete}, extract::Path};
let app = Router::new()
.route("/", get(root))
.route("/users", get(list_users).post(create_user))
.route("/users/:id", get(show_user))
.route("/api/:version/users/:id/action", delete(do_users_action))
.route("/assets/*path", get(serve_asset));
async fn root() {}
async fn list_users() {}
async fn create_user() {}
async fn show_user(Path(id): Path<u64>) {}
async fn do_users_action(Path((version, id)): Path<(String, u64)>) {}
async fn serve_asset(Path(path): Path<String>) {}
如果路径与另一个路由重叠,则会发生panic
use axum::{routing::get, Router};
let app = Router::new()
.route("/", get(|| async {}))
.route("/", get(|| async {}));
静态路由 /foo 和动态路由 /:key 不被视为重叠,并且 /foo 将优先。
如果路径为空,也会引发 panic。
添加另一个路由到路由器调用一个服务
pub fn route_service<T>(self, path: &str, service: T) -> Self
where
T: Service<Request, Error=Infallible> + Clone + Send + 'static,
T::Response: IntoResponse,
T::Future: Send + 'static,
示例:
use axum::{
Router,
body::Body,
routing::{any_service, get_service},
extract::Request,
http::StatusCode,
error_handling::HandleErrorLayer,
};
use tower_http::services::ServeFile;
use http::Response;
use std::{convert::Infallible, io};
use tower::service_fn;
let app = Router::new()
.route(
"/",
any_service(service_fn(|_: Request| async {
let res = Response::new(Body::from("Hi from `GET /`"));
}))
)
.route_service(
"/foo",
service_fn(|req: Request| async move {
let body = Body::from(format!("Hi from `{}` /foo", req.method()))
let res = Response::new(body);
Ok::<_, Infallible>(res)
})
)
.route_service(
"/static/Cargo.toml",
ServeFile::new("Cargo.toml"),
);
以这种方式路由到任意服务会对背压(Service::poll_ready)产生复杂性。
有关更多详细信息,请参阅服务路由和背压模块。
由于相同的原因而出现panic,或者尝试将路由到Router时也会发生panic。
use axum::{routing::get, Router};
let app = Router::new().route_service(
"/",
Router::new().route("/foo", get(|| async {})),
);
在某个路径上嵌套一个路由器。
这样可以将应用程序分解成更小的部分,并将它们组合在一起。
pub fn nest(self, path: &str, router: Router<S>) -> Self
示例:
use axum::{
routing::{get, post},
Router,
};
let user_routes = Router::new().route("/:id", get(|| async {}));
let team_routes = Router::new().route("/", post(|| async {}));
let api_routes = Router::new()
.nest("/users", user_routes)
.nest("/teams", team_routes);
let app = Router::new().nest("/api", api_routes);
请注意,嵌套路由将无法看到原始请求URI,而是会剥去匹配的前缀。
这对于像静态文件服务之类的服务工作是必要的。
如果需要原始请求URI,请使·OriginalUri。
在使用嵌套动态路由时要小心,因为嵌套还会从外部路由中捕获:
use axum::{
extract::Path,
routing::get,
Router,
};
use std::collections::HashMap;
async fn users_get(Path(params): Path<HashMap<String, String>>) {
let version = params.get("version");
let id = params.get("id");
}
let users_api = Router::new().route("/users/:id", get(users_get));
let app = Router::new().nest("/:version/api", users_api);
嵌套路由类似于通配符路由。
不同之处在于通配符路由仍然可以看到整个 URI,而嵌套路由将会去掉前缀:
use axum::{routing::get, http::Uri, Router};
let nested_router = Router::new()
.route("/", get(|uri: Uri| async {
}));
let app = Router::new()
.route("/foo/*rest", get(|uri: Uri| async {
}))
.nest("/bar", nested_router);
如果嵌套路由器没有自己的回退,则将从外部路由器继承回退:
use axum::{routing::get, http::StatusCode, handler::Handler, Router};
async fn fallback() -> (StatusCode, &'static str) {
(StatusCode::NOT_FOUND, "Not Found")
}
let api_routes = Router::new().route("/users", get(|| async {}));
let app = Router::new()
.nest("/api", api_routes)
.fallback(fallback);
在这里,像 GET /api/not-found 这样的请求将进入 api_routes,
但由于它没有匹配的路由,也没有自己的回退,它将调用外部路由器的回退,即回退功能。
如果嵌套路由器有自己的回退,则外部回退将不会被继承:
use axum::{
routing::get,
http::StatusCode,
handler::Handler,
Json,
Router,
};
async fn fallback() -> (StatusCode, &'static str) {
(StatusCode::NOT_FOUND, "Not Found")
}
async fn api_fallback() -> (StatusCode, Json<serde_json::Value>) {
(
StatusCode::NOT_FOUND,
Json(serde_json::json!({ "status": "Not Found" })),
)
}
let api_routes = Router::new()
.route("/users", get(|| async {}))
.fallback(api_fallback);
let app = Router::new()
.nest("/api", api_routes)
.fallback(fallback);
在这里,像 GET /api/not-found 这样的请求将转到 api_fallback。
当使用此方法将Router组合时,每个Router必须具有相同类型的状态。
如果您的路由器具有不同类型,您可以使用Router::with_state来提供状态并使类型匹配:
use axum::{
Router,
routing::get,
extract::State,
};
#[derive(Clone)]
struct InnerState {}
#[derive(Clone)]
struct OuterState {}
async fn inner_handler(state: State<InnerState>) {}
let inner_router = Router::new()
.route("/bar", get(inner_handler))
.with_state(InnerState {});
async fn outer_handler(state: State<OuterState>) {}
let app = Router::new()
.route("/", get(outer_handler))
.nest("/foo", inner_router)
.with_state(OuterState {});
请注意,内部路由器仍将继承外部路由器的后备机制。
- 如果路由与另一个路由重叠。有关详细信息,请参阅
Router::route。
- 如果路由包含通配符(
*)。
- 如果
path为空。
pub fn nest_service<T>(self, path: &str, service: T) -> Self
where
T: Service<Request, Error=Infallible> + Clone + Send + 'static,
T::Response: IntoResponse,
T::Future: Send + 'static,
pub fn merge<R>(self, other: R) -> Self
where
R: Into<Router<S>>,
这对于将应��用程序分成更小的部分并将它们组合成一个非常有用。
use axum::{
routing::get,
Router,
};
let user_routes = Router::new()
.route("/users", get(users_list))
.route("/users/:id", get(users_show));
let team_routes = Router::new()
.route("/teams", get(teams_list));
let app = Router::new()
.merge(user_routes)
.merge(team_routes);
使用此方法合并 Router 时,每个 Router 必须具有相同类型的状态。
如果您的 routers 具有不同类型,可以使用 Router::with_state 来提供状态并使类型匹配:
use axum::{
Router,
routing::get,
extract::State,
};
#[derive(Clone)]
struct InnerState {}
#[derive(Clone)]
struct OuterState {}
async fn inner_handler(state: State<InnerState>) {}
let inner_router = Router::new()
.route("/bar", get(inner_handler))
.with_state(InnerState {});
async fn outer_handler(state: State<OuterState>) {}
let app = Router::new()
.route("/", get(outer_handler))
.merge(inner_router)
.with_state(OuterState {});
使用此方法合并 Router 时,后备(fallbacks)也会合并。但是只能有一个路由器有后备。
pub fn layer<L>(self, layer: L) -> Router<S>
where
L: Layer<Route> + Clone + Send + 'static,
L::Service: Service<Request> + Clone + Send + 'static,
<L::Service as Service<Request>>::Response: IntoResponse + 'static,
<L::Service as Service<Request>>::Error: Into<Infallible> + 'static,
<L::Service as Service<Request>>::Future: Send + 'static,
这可以用于为一组路由的请求添加额外的处理。
注意,中间件只应用于现有路由。
因此,您必须首先添加您的路由(和/或回退(fallbacks)),然后调用层(layer)。
在调用层之后添加的额外路由将不会添加中间件。
如果要将中间件添加到单个处理程序,可以使用 MethodRouter::layer 或 Handler::layer。
示例
添加tower_http::trace::TraceLayer:
use axum::{
routing::get,
Router,
};
use tower_http::trace::TraceLayer;
let app = Router::new()
.route("/foo", get(|| async {}))
.route("/bar", get(|| async {}))
.layer(TraceLayer::new_for_http());
如果您需要编写自己的中间件,请参阅“编写中间件”以获取不同的选项。
如果您只想在某些路由上使用中间件,可以使用Router::merge:
use axum::{
routing::get,
Router,
};
use tower_http::{trace::TraceLayer, compression::CompressionLayer};
let with_tracing = Router::new()
.route("/foo", get(|| async {}))
.layer(TraceLayer::new_for_http());
let with_compression = Router::new()
.route("/bar", get(|| async {}))
.layer(CompressionLayer::new());
let app = Router::new()
.merge(with_tracing)
.merge(with_compression);
当应用多个中间件时,建议使用tower::ServiceBuilder。有关更多详细信息,请参阅中间件。
使用此方法添加的中间件将在路由之后运行,因此无法用于重写请求URI。
有关更多详细信息和解决方法,请参见“在中间件中重写请求URI”。
请参阅有关错误处理影响中间件的详细信息。
pub fn route_layer<L>(self, layer: L) -> Self
where
L: Layer<Route> + Clone + Send + 'static,
L::Service: Service<Request> + Clone + Send + 'static,
<L::Service as Service<Request>>::Response: IntoResponse + 'static,
<L::Service as Service<Request>>::Error: Into<Infallible> + 'static,
<L::Service as Service<Request>>::Future: Send + 'static,
请注意,中间件仅应用于现有路由。
因此,您必须首先添加您的路由(和/或回调),然后在之后调用 route_layer。
调用 route_layer 后添加的额外路由将不会添加中间件。
这与 Router::layer 类似,不同之处在于只有当请求匹配路由时中间件才会运行。
这对于提前返回的中间件非常有用(例如授权),
否则可能会将 404 Not Found 转换为 401 Unauthorized。
示例
use axum::{
routing::get,
Router,
};
use tower_http::validate_request::ValidateRequestHeaderLayer;
let app = Router::new()
.route("/foo", get(|| async {}))
.route_layer(ValidateRequestHeaderLayer::bearer("password"));
pub fn fallback<H, T>(self, handler: H) -> Self
where
H: Handler<T, S>,
T: 'static
如果没有任何路由匹配传入的请求,将调用此服务。
use axum::{
routing::get,
Router,
handler::Handler,
response::IntoResponse,
http::{StatusCode, Uri},
};
let app = Router::new()
.route("/foo", get(|| async { "foo" }))
.fallback(fallback);
async fn fallback(uri: Uri) -> (StatusCode, String) {
(StatusCode::NOT_FOUND, format!("No route for {uri}"))
}
仅在路由器中没有匹配任何内容的路由时才适用回退。
如果处理程序被请求匹配但返回 404,则不会调用回退。
如果没有其他路由,使用Router::new().fallback(...)来接受所有请求,
无论路径或方法如何,这并不是最佳选择:
use axum::Router;
async fn handler() {}
let app = Router::new().fallback(handler);
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, app).await.unwrap();
直接运行处理程序会更快,因为它避免了路由的开销:
use axum::handler::HandlerWithoutStateExt;
async fn handler() {}
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, handler.into_make_service()).await.unwrap();
pub fn fallback_service<T>(self, service: T) -> Self
where
T: Service<Request, Error=Infallible> + Clone + Send + 'static,
T::Response: IntoResponse,
T::Future: Send + 'static,
查看Router::fallback以获取更多详细信息。
pub fn with_state<S2>(self, state: S) -> Router<S2>
use axum::{Router, routing::get, extract::State};
#[derive(Clone)]
struct AppState {}
let routes = Router::new()
.route("/", get(|State(state): State<AppState>| async {
}))
.with_state(AppState {});
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, routes).await.unwrap();
在从函数返回 Router 时,通常建议不直接设置状态
use axum::{Router, routing::get, extract::State};
#[derive(Clone)]
struct AppState {}
fn routes() -> Router<AppState> {
Router::new()
.route("/", get(|_: State<AppState>| async {}))
}
let routes = routes().with_state(AppState {});
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, routes).await.unwrap();
如果确实需要提供状态,并且您没有将路由嵌套/合并到另一个路由器中,则返回不带任何类型参数的 Router:
fn routes(state: AppState) -> Router {
Router::new()
.route("/", get(|_: State<AppState>| async {}))
.with_state(state)
}
let routes = routes(AppState {});
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, routes).await.unwrap();
这是因为我们只能在 Router<()> 上调用 Router::into_make_service,
而不能在 Router<AppState> 上调用。有关原因的更多详细信息,请参见下文。
请注�意,状态默认为(),所以Router和Router<()>是一样的。
如果您需要嵌套/合并路由器,建议在结果路由器上使用通用状态类型:
fn routes<S>(state: AppState) -> Router<S> {
Router::new()
.route("/", get(|_: State<AppState>| async {}))
.with_state(state)
}
let routes = Router::new().nest("/api", routes(AppState {}));
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, routes).await.unwrap();
传递给此方法的状态将用于该路由器接收的所有请求。
这意味着它不适合保存从请求中派生的状态,比如在中间件中提取的授权数据。
请改用 Extension 来存储此类数据。
Router<S>表示一个缺少类型为S的状态以处理请求的路由器。
它并不意味着具有类型为S的状态的路由器。
例如:
let router: Router<AppState> = Router::new()
.route("/", get(|_: State<AppState>| async {}));
let router: Router<()> = router.with_state(AppState {});
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, router).await.unwrap();
或许有点反直觉,Router::with_state 并不总是返回一个 Router<()>。
相反,您可以选择新的缺失状态类型是什么:
let router: Router<AppState> = Router::new()
.route("/", get(|_: State<AppState>| async {}));
let string_router: Router<String> = router.with_state(AppState {});
let string_router = string_router
.route("/needs-string", get(|_: State<String>| async {}));
let final_router: Router<()> = string_router.with_state("foo".to_owned());
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, final_router).await.unwrap();
为什么在调用with_state后返回Router<AppState>不起作用?
fn routes(state: AppState) -> Router<AppState> {
Router::new()
.route("/", get(|_: State<AppState>| async {}))
.with_state(state)
}
let app = routes(AppState {});
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, app).await.unwrap();
由于我们提供了所需的所有状态,因此请返回 Router<()>。
fn routes(state: AppState) -> Router<()> {
Router::new()
.route("/", get(|_: State<AppState>| async {}))
.with_state(state)
}
let app = routes(AppState {});
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, app).await.unwrap();
如果您需要一个实现 Service 但不需要任何状态的 Router(也许您正在制作一个在内部使用 axum 的库),
那么建议在开始提供请求之前调用该方法:
use axum::{Router, routing::get};
let app = Router::new()
.route("/", get(|| async { }))
.with_state(());
这不是必需的,但它让 axum 有机会更新路由器中的一些内部内容,可能会影响性能并减少分配。
请注意,Router::into_make_service 和 Router::into_make_service_with_connect_info 会自动执行此操作。
pub fn as_service<B>(&mut self) -> RouterAsService<'_, B, S>
在某些情况下,在 Router 上调用 tower::ServiceExt 的方法时,可能会出现类似以下内容的类型推断错误
let response = router.ready().await?.call(request).await?;
^^^^^ cannot infer type for type parameter `B`
这是因为 Router 使用 impl<B> Service<Request<B>> for Router<()> 实现了 Service。
例如:
use axum::{
Router,
routing::get,
http::Request,
body::Body,
};
use tower::{Service, ServiceExt};
let mut router = Router::new().route("/", get(|| async {}));
let request = Request::new(Body::empty());
let response = router.ready().await?.call(request).await?;
调用 Router::as_service 可以解决此问题。
use axum::{
Router,
routing::get,
http::Request,
body::Body,
};
use tower::{Service, ServiceExt};
let mut router = Router::new().route("/", get(|| async {}));
let request = Request::new(Body::empty());
let response = router.as_service().ready().await?.call(request).await?;
这主要是在测试时调用路由时使用的。当通过 Router::into_make_service 正常运行路由时,这是不必要的。
pub fn into_service<B>(self) -> RouterIntoService<B, S>
这与 Router::as_service 相同,只是它返回一个拥有的服务。有关更多详细信息,请参见该方法。
将此路由器转换为一个 MakeService,它是一个响应是另一个服务的服务。
use axum::{
routing::get,
Router,
};
let app = Router::new().route("/", get(|| async { "Hi!" }));
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, app).await.unwrap();
pub fn into_make_service_with_connect_info<C>(
self
) -> IntoMakeServiceWithConnectInfo<Self, C>
将这个路由器转换为一个MakeService,它将把C的相关ConnectInfo存储在一个请求扩展中,
以便ConnectInfo可以提取它。
这使得可以提取类似客户端远程地址的信息。
提取std::net::SocketAddr 是开箱即用的。
use axum::{
extract::ConnectInfo,
routing::get,
Router,
};
use std::net::SocketAddr;
let app = Router::new().route("/", get(handler));
async fn handler(ConnectInfo(addr): ConnectInfo<SocketAddr>) -> String {
format!("Hello {addr}")
}
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, app.into_make_service_with_connect_info::<SocketAddr>()).await.unwrap();
您可以这样实现自定义连接(Connected):
use axum::{
extract::connect_info::{ConnectInfo, Connected},
routing::get,
serve::IncomingStream,
Router,
};
let app = Router::new().route("/", get(handler));
async fn handler(
ConnectInfo(my_connect_info): ConnectInfo<MyConnectInfo>,
) -> String {
format!("Hello {my_connect_info:?}")
}
#[derive(Clone, Debug)]
struct MyConnectInfo {
}
impl Connected<IncomingStream<'_>> for MyConnectInfo {
fn connect_info(target: IncomingStream<'_>) -> Self {
MyConnectInfo {
}
}
}
let listener = tokio::net::TcpListener::bind("0.0.0.0:3000").await.unwrap();
axum::serve(listener, app.into_make_service_with_connect_info::<MyConnectInfo>()).await.unwrap();
fn clone(&self) -> Self: 返回一个克隆值。fn clone_from(&mut self, source: &Self): 从源(source)执行复制赋值。
fn fmt(&self, f: &mut Formatter<'_>) -> Result: 使用给定的格式器格式化值
fn default() -> Self: 返回一个默认值。
- 仅在 tokio crate 功能和 (crate 功能
http1 或 http2) 中可用。
fn poll_ready(&mut self, _cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>>
- 当服务能够处理请求时,返回
Poll::Ready(Ok(()))。
impl<B> Service<Request<B>> for Router<()>
where
B: HttpBody<Data = Bytes> + Send + 'static,
B::Error: Into<BoxError>,
type Response = Response<Body>
fn poll_ready(&mut self, _: &mut Context<'_>) -> Poll<Result<(), Self::Error>>
- 当服务能够处理请求时,返回
Poll::Ready(Ok(()))。
impl<S> Freeze for Router<S>impl<S = ()> !RefUnwindSafe for Router<S>impl<S> Send for Router<S>impl<S> Sync for Router<S>impl<S> Unpin for Router<S>impl<S = ()> !UnwindSafe for Router<S>
impl<T> Any for T
where
T: 'static + ?Sized,
impl<T> Borrow<T> for T
where
T: ?Sized,
impl<T> BorrowMut<T> for T
where
T: ?Sized,
impl<T> From<T> for T
impl<T> FromRef<T> for T
where
T: Clone,
impl<T> Instrument for T
impl<T, U> Into<U> for T
where
U: From<T>,
impl<M, S, Target, Request> MakeService<Target, Request> for M
where
M: Service<Target, Response = S>,
S: Service<Request>,
impl<T> PolicyExt for T
where
T: ?Sized,
impl<T> Same for T
impl<S, R> ServiceExt<R> for S
where
S: Service<R>,
impl<T, Request> ServiceExt<Request> for T
where
T: Service<Request> + ?Sized,
impl<T> ToOwned for T
where
T: Clone,
impl<T, U> TryFrom<U> for T
where
U: Into<T>,
impl<T, U> TryInto<U> for T
where
U: TryFrom<T>,
impl<V, T> VZip<V> for T
where
V: MultiLane<T>,
impl<T> WithSubscriber for T